Cambios de liderazgo en Bluetab EMEA
Bluetab
an IBM Company

Alfonso Zamora
Cloud Engineer

El objetivo principal de este artículo es presentar una solución para el análisis y la ingeniería de datos desde el punto de vista del personal de negocio, sin requerir unos conocimientos técnicos especializados.
Las compañías disponen de una gran cantidad de procesos de ingeniería del dato para sacarle el mayor valor a su negocio, y en ocasiones, soluciones muy complejas para el caso de uso requerido. Desde aquí, proponemos simplificar la operativa para que un usuario de negocio, que anteriormente no podía llevar a cabo el desarrollo y la implementación de la parte técnica, ahora será autosuficiente, y podrá implementar sus propias soluciones técnicas con lenguaje natural.
Para poder cumplir nuestro objetivo, vamos a hacer uso de distintos servicios de la plataforma Google Cloud para crear tanto la infraestructura necesaria como los distintos componentes tecnológicos para poder sacar todo el valor a la información empresarial.
Antes de comenzar con el desarrollo del artículo, vamos a explicar algunos conceptos básicos sobre los servicios y sobre distintos frameworks de trabajo que vamos a utilizar para la implementación:
Un LLM (Large Language Model) es un tipo de algoritmo de inteligencia artificial (IA) que utiliza técnicas de deep learning y enormes conjuntos de datos para comprender, resumir, generar y predecir nuevos contenidos. Un ejemplo de LLM podría ser ChatGPT que hace uso del modelo GPT desarrollado por OpenAI.
En nuestro caso, vamos a hacer uso del modelo Codey[6] (code-bison) que es un modelo implementado por Google que está optimizado para generar código ya que ha sido entrenado para esta especialización que se encuentra dentro del stack de VertexAI[7]
Y no solo es importante el modelo que vamos a utilizar, sino también el cómo lo vamos a utilizar. Con esto, me refiero a que es necesario comprender los parámetros de entrada que afectan directamente a las respuestas que nos dará nuestro modelo, en los que podemos destacar los siguientes:
Una vez que hemos definido los parámetros y sabemos bien para qué sirve cada uno de ellos y comprendemos lo que es un prompt, vamos a enfocarnos en cómo utilizarlo e implementar uno que se pueda adaptar a nuestras necesidades.
Como se ha comentado anteriormente, el objetivo es generar tanto código Pyspark como terraform para poder realizar las tareas de creación de infraestructura y tratamiento del dato. Como son tareas totalmente distintas, como primera decisión importante para nuestro prompt se ha optado por dividirlo en dos partes específicas para que cada prompt esté entrenado con ejemplos para generar un lenguaje u otro.
Para cada uno de los prompt, se hace una introducción para especificar cuál va a ser el objetivo y qué peticiones se van a realizar, y después una serie de ejemplos en los que se le da un input en lenguaje natural simulando una petición, y posteriormente también se le da el output deseado para asignar el texto al código específico. El objetivo es generar un prompt estructurado que pueda ser procesado de manera eficiente por el modelo para que en los siguientes casos, pueda asociar los ejemplos que tiene disponibles con respuestas adecuadas.
Vamos a poner en práctica estos pequeños tips para ver una de las entradas al prompt de terraform:
input: I need to read a file named `myfile.csv` inside the folder `data/input` in a bucket called `application-data-input`, and I need to create a new dataset and table in BigQuery called `tst_tf_ai`. The process has to read the file, remove the first three characters of the name, and write the result in BigQuery. The schema of the table will be ‘name’ of String type and ‘surname’ of String type. The infrastructure has to be deployed in the project `project-cloud-223` in GCP, and region `europe-southwest1`.
output: «`hcl
terraform {
required_version = «>= 0.15»
required_providers {
google = «~> 5.0»
}
}resource «google_storage_bucket» «temporary_files» {
project = «project-cloud-223»
name = «temporary-files-dataproc»
location = «europe-southwest1»
force_destroy = true
}resource «google_storage_bucket» «bucket1» {
project = «project-cloud-223»
name = «application-data-input»
location = «europe-southwest1»
force_destroy = true
}resource «google_storage_bucket_object» «folder1» {
name = «data/input/»
bucket = google_storage_bucket.bucket1.name
content = » «
}resource «google_bigquery_dataset» «dataset» {
project = «project-cloud-223»
dataset_id = «tst_tf_ai»
friendly_name = «tst_tf_ai»
description = «Description»
location = «europe-southwest1»
}resource «google_bigquery_table» «table» {
project = «project-cloud-223»
dataset_id = google_bigquery_dataset.dataset.dataset_id
deletion_protection = false
table_id = «tst_tf_ai»
schema = <<EOF
[
{
«name»: «name»,
«type»: «STRING»,
«mode»: «NULLABLE»,
«description»: «The name»
},
{
«name»: «surname»,
«type»: «STRING»,
«mode»: «NULLABLE»,
«description»: «The surname»
}
]
EOF
}
«`
Es importante implementar ejemplos lo más parecido posible a tu caso de uso para que las respuestas sean más precisas, y también que tenga bastantes ejemplos con variedad de peticiones para que sea más inteligente a la hora de devolver las respuestas. Una de las prácticas para que sea más interactiva la implementación del prompt, puede ser ir probando con distintas peticiones, y si no es capaz de hacer lo que se le ha pedido, se debería modificar las instrucciones.
Como hemos podido observar, el desarrollo del prompt sí necesitamos conocimientos técnicos para poder traducir las peticiones a código, por lo que esta tarea sí se debería de abordar por una persona técnica para posteriormente evadir a la persona de negocio. En otras palabras, necesitamos que una persona técnica genere la primera base de conocimiento para que luego las personas de negocio puedan hacer uso de este tipo de herramientas.
También se ha podido ver, que la generación de código en terraform es más compleja que la generación en Pyspark, por lo que se han requerido de más ejemplos de entrada en la realización del prompt de terraform para que se ajuste a nuestro caso de uso. Por ejemplo, hemos aplicado en los ejemplos que en terraform siempre cree un bucket temporal (temporary-files-dataproc) para que pueda ser utilizado por Dataproc.
Se han realizado tres ejemplos con peticiones distintas, requiriendo más o menos infraestructura y transformaciones para ver si nuestro prompt es lo suficientemente robusto.
En el archivo ai_gen.py vemos el código necesario para hacer las peticiones y los tres ejemplos, en el que cabe destacar la configuración escogida para los parámetros del modelo:
Vamos a realizar un ejemplo de petición que está disponible en el siguiente repositorio github, en el que está detallado en el README paso por paso para poder ejecutarlo tú mismo. La petición es la siguiente:
In the realm of ‘customer_table,’ my objective is the seamless integration of pivotal fields such as ‘customer_id’, ‘name’, and ‘email’. These components promise to furnish crucial insights into the essence of our valued customer base.Conversely, when delving into the nuances of ‘sales_table,’ the envisioned tapestry includes essential elements like ‘order_id’ ‘product’ ‘price’, ‘amount’ and ‘customer_id’. Theseattributes, meticulously curated, will play a pivotal role in the nuanced exploration and analysis of sales-related data.
The ‘bigtable_info’ table will have all the fields resulting from the union of the two tables, ‘customer_table’ and ‘sales_table.’ Here, the outcome of joining the two tables by the ‘customer_id’ numeric field will be stored.
Furthermore, as part of our meticulous data collection strategy, I plan to inaugurate a dedicated Google Cloud Storage bucket christened ‘sales-etl-bucket.’ This repository is strategically designed to serve as a robust container for collating data, particularly hailing from CSV files. This endeavor is set to enhance the efficiency and organizational prowess of our data management processes.
To enhance the structure, two distinct subfolders, ‘input/sales’ and ‘input/customers’ have been ingeniously incorporated within the ‘sales-etl-bucket,’ ensuring a refined organization of the incoming data streams.
You will need to read the CSV files within the ‘input/sales’ folder to write the data into the ‘sales_table’. Additionally, you should perform the same operation with the files from the ‘input/customers’ folder to write the data into the ‘customer_table’. Finally, you are required to perform a join between the sales and customers information based on the ‘customer_id’ number field and write the merged information into the ‘bigtable_info’.
Ejecutamos y vamos a analizar las salidas generadas en las carpetas generated/customers/python/etl.py y generated/terraform/main.tf.:
terraform {
required_version = ">= 0.15"
required_providers {
google = "~> 5.0"
}
}
resource "google_storage_bucket" "temporary_files" {
project = "my-cloud-project"
name = "temporary-files-dataproc"
location = "europe-southwest1"
force_destroy = true
}
resource "google_storage_bucket" "sales_etl_bucket" {
project = "my-cloud-project"
name = "sales-etl-bucket"
location = "europe-southwest1"
force_destroy = true
}
resource "google_storage_bucket_object" "sales_folder" {
name = "input/sales/"
bucket = google_storage_bucket.sales_etl_bucket.name
content = " "
}
resource "google_storage_bucket_object" "customers_folder" {
name = "input/customers/"
bucket = google_storage_bucket.sales_etl_bucket.name
content = " "
}
resource "google_bigquery_dataset" "raw_sales_data" {
project = "my-cloud-project"
dataset_id = "raw_sales_data"
friendly_name = "Raw Sales Data"
description = "This dataset contains the raw sales data."
location = "europe-southwest1"
}
resource "google_bigquery_table" "customer_table" {
project = "my-cloud-project"
dataset_id = google_bigquery_dataset.raw_sales_data.dataset_id
deletion_protection = false
table_id = "customer_table"
schema = <<EOF
[
{
"name": "customer_id",
"type": "INT64",
"mode": "REQUIRED",
"description": "The customer ID."
},
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE",
"description": "The customer's name."
},
{
"name": "email",
"type": "STRING",
"mode": "NULLABLE",
"description": "The customer's email address."
}
]
EOF
}
resource "google_bigquery_table" "sales_table" {
project = "my-cloud-project"
dataset_id = google_bigquery_dataset.raw_sales_data.dataset_id
deletion_protection = false
table_id = "sales_table"
schema = <<EOF
[
{
"name": "order_id",
"type": "INT64",
"mode": "REQUIRED",
"description": "The order ID."
},
{
"name": "product",
"type": "STRING",
"mode": "NULLABLE",
"description": "The product name."
},
{
"name": "price",
"type": "FLOAT64",
"mode": "NULLABLE",
"description": "The product price."
},
{
"name": "amount",
"type": "INT64",
"mode": "NULLABLE",
"description": "The product amount."
},
{
"name": "customer_id",
"type": "INT64",
"mode": "REQUIRED",
"description": "The customer ID."
}
]
EOF
}
resource "google_bigquery_dataset" "master_sales_data" {
project = "my-cloud-project"
dataset_id = "master_sales_data"
friendly_name = "Master Sales Data"
description = "This dataset contains the master sales data."
location = "europe-southwest1"
}
resource "google_bigquery_table" "bigtable_info" {
project = "my-cloud-project"
dataset_id = google_bigquery_dataset.master_sales_data.dataset_id
deletion_protection = false
table_id = "bigtable_info"
schema = <<EOF
[
{
"name": "customer_id",
"type": "INT64",
"mode": "REQUIRED",
"description": "The customer ID."
},
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE",
"description": "The customer's name."
},
{
"name": "email",
"type": "STRING",
"mode": "NULLABLE",
"description": "The customer's email address."
},
{
"name": "order_id",
"type": "INT64",
"mode": "REQUIRED",
"description": "The order ID."
},
{
"name": "product",
"type": "STRING",
"mode": "NULLABLE",
"description": "The product name."
},
{
"name": "price",
"type": "FLOAT64",
"mode": "NULLABLE",
"description": "The product price."
},
{
"name": "amount",
"type": "INT64",
"mode": "NULLABLE",
"description": "The product amount."
}
]
EOF
}
Vemos que va a añadir un bucket con dos carpetas para poder subir los datos a la carpeta correspondiente dependiendo si es sales o customer. También ha creado dos datasets, uno para la capa de raw para tener los datos según nos han venido de origen con las tablas de customers y sales, y el segundo dataset para la tabla final que almacenará el resultado de juntar la información de ambas tablas.
Vamos a revisar el código pyspark:
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# Configure Spark session
spark = SparkSession.builder.appName("SalesETL").getOrCreate()
# Define file paths
sales_path = "gs://sales-etl-bucket/input/sales/*.csv"
customers_path = "gs://sales-etl-bucket/input/customers/*.csv"
# Read CSV files into DataFrames
sales_df = spark.read.csv(sales_path, header=True, inferSchema=True)
customers_df = spark.read.csv(customers_path, header=True, inferSchema=True)
# Write tables to BigQuery
sales_df.write.format("bigquery") \
.option("temporaryGcsBucket", "temporary-files-dataproc") \
.option("table", "raw_sales_data.sales_table") \
.mode("overwrite") \
.save()
customers_df.write.format("bigquery") \
.option("temporaryGcsBucket", "temporary-files-dataproc") \
.option("table", "raw_sales_data.customer_table") \
.mode("overwrite") \
.save()
# Join sales and customers tables
bigtable_info_df = sales_df.join(customers_df, on="customer_id", how="inner")
# Write joined table to BigQuery
bigtable_info_df.write.format("bigquery") \
.option("temporaryGcsBucket", "temporary-files-dataproc") \
.option("table", "master_sales_data.bigtable_info") \
.mode("overwrite") \
.save()
# Stop the Spark session
spark.stop()
Se puede observar que el código generado realiza la lectura por cada una de las carpetas e inserta cada dato en su tabla correspondiente.
Para poder asegurarnos de que el ejemplo está bien realizado, podemos seguir los pasos del README en el repositorio GitHub[8] para aplicar los cambios en el código terraform, subir los ficheros de ejemplo que tenemos en la carpeta example_data y a ejecutar un Batch en Dataproc.
Finalmente, vemos si la información que se ha almacenado en BigQuery es correcta:
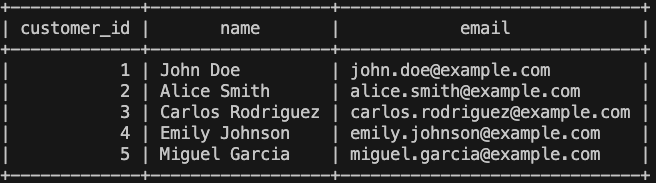
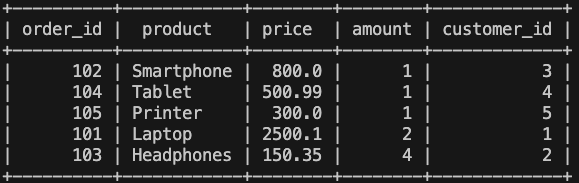

De esta forma, hemos conseguido de a través de lenguaje natural, tener un proceso funcional totalmente operativo. Hay otro ejemplo que se puede ejecutar, aunque también animo a hacer más ejemplos, o incluso mejorar el prompt, para poder meterle ejemplos más complejos, y también adaptarlo a tu caso de uso.
Al ser ejemplos muy concretos sobre unas tecnologías tan concretas, cuando se hace un cambio en el prompt en cualquier ejemplo puede afectar a los resultados, o también, modificar alguna palabra de la petición de entrada. Esto se traduce en que el prompt no es lo suficientemente robusto como para poder asimilar distintas expresiones sin afectar al código generado. Para poder tener un prompt y un sistema productivo, se necesita más entrenamiento y distinta variedad tanto de soluciones, peticiones, expresiones,. … Con todo ello, finalmente podremos tener una primera versión que poder presentar a nuestro usuario de negocio para que sea autónomo.
Especificar el máximo detalle posible a un LLM es crucial para obtener resultados precisos y contextuales. Aquí hay varios consejos que debemos tener en cuenta para poder tener un resultado adecuado:
En el ámbito de LLM, las líneas futuras de desarrollo se centran en mejorar la eficiencia y la accesibilidad de la implementación de modelos de lenguaje. Aquí se detallan algunas mejoras clave que podrían potenciar significativamente la experiencia del usuario y la eficacia del sistema:
1. Uso de distintos modelos de LLM:
La inclusión de una función que permita a los usuarios comparar los resultados generados por diferentes modelos sería esencial. Esta característica proporcionaría a los usuarios información valiosa sobre el rendimiento relativo de los modelos disponibles, ayudándoles a seleccionar el modelo más adecuado para sus necesidades específicas en términos de precisión, velocidad y recursos requeridos.
2. Capacidad de retroalimentación del usuario:
Implementar un sistema de retroalimentación que permita a los usuarios calificar y proporcionar comentarios sobre las respuestas generadas podría ser útil para mejorar continuamente la calidad del modelo. Esta información podría utilizarse para ajustar y refinar el modelo a lo largo del tiempo, adaptándose a las preferencias y necesidades cambiantes de los usuarios.
3. RAG (Retrieval-augmented generation)
RAG (Retrieval-augmented generation) es un enfoque que combina la generación de texto y la recuperación de información para mejorar las respuestas de los modelos de lenguaje. Implica el uso de mecanismos de recuperación para obtener información relevante de una base de datos o corpus textual, que luego se integra en el proceso de generación de texto para mejorar la calidad y la coherencia de las respuestas generadas.
Cloud Storage[1]: https://cloud.google.com/storage/docs
BigQuery[2]: https://cloud.google.com/bigquery/docs
Terraform[3]: https://developer.hashicorp.com/terraform/docs
PySpark[4]: https://spark.apache.org/docs/latest/api/python/index.html
Dataproc[5]: https://cloud.google.com/dataproc/docs
Codey[6]: https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/code-generation
VertexAI[7]: https://cloud.google.com/vertex-ai/docs
GitHub[8]: https://github.com/alfonsozamorac/etl-genai

AWS Cloud Architect

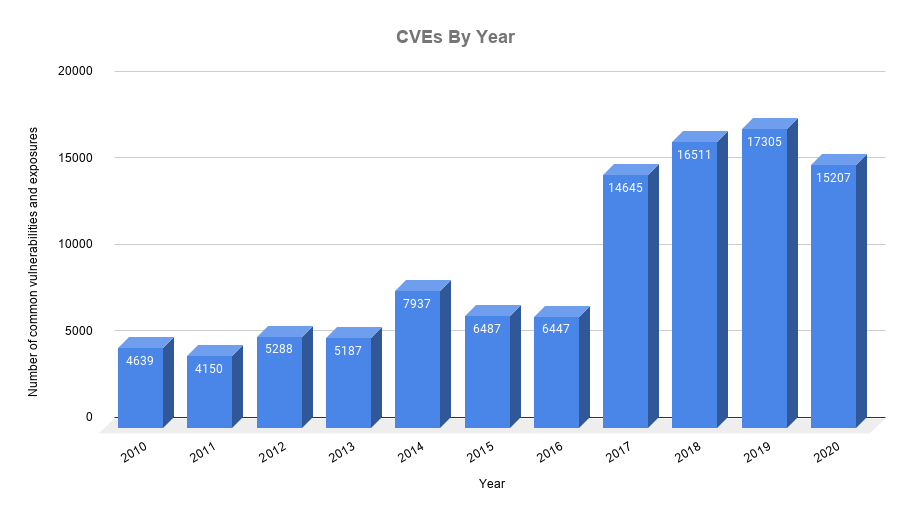
CVE es una lista de información mantenida por MITRE Corporation cuyo objetivo es centralizar el registro de vulnerabilidades de seguridad conocidas, en la que cada referencia tiene un número de identificación CVE-ID, descripción de la vulnerabilidad, que versiones del software están afectadas, posible solución al fallo (si existe) o como configurar para mitigar la vulnerabilidad y referencias a publicaciones o entradas de foros o blog donde se ha hecho pública la vulnerabilidad o se demuestra su explotación.
El CVE-ID ofrece una nomenclatura estándar para identificar de forma inequívoca una vulnerabilidad. Se clasifican en 5 tipologías, las cuales veremos en la sección Interpretación del análisis. Dichas tipologías son asignadas basándose en diferentes métricas (si tenéis curiosidad, consultad CVSS v3 Calculator)
CVE se ha convertido en el estándar para el registro de vulnerabilidades, por lo que la amplia mayoría de empresas de tecnología y particulares hacen uso de la misma.
Disponemos de múltiples canales para estar informados de todas las novedades referentes a vulnerabilidades: blog oficial, twitter, repositorio cvelist en github o LinkedIn.
Adicionalmente, si queréis información más detallada sobre una vulnerabilidad, podéis consultar la web del NIST, en concreto la NVD (National Vulnerability Database)
Os invitamos a buscar alguna de las siguientes vulnerabilidades críticas, es muy posible que de forma directa o indirecta os haya podido afectar. Os adelantamos que han sido de las más sonadas 
Si detectas una vulnerabilidad, te animamos a registrarla a través del siguiente formulario

Roger Pou Lopez
Data Scientist

Un RAG, acrónimo de «Retrieval Augmented Generation», representa una estrategia innovadora dentro del procesamiento de lenguaje natural. Se integra con los Grandes Modelos de Lenguaje (LLM, por sus siglas en inglés), tales como los que usa ChatGPT internamente (GPT-3.5-turbo o GPT-4), con el objetivo de mejorar la calidad de la respuesta y reducir ciertos comportamientos no deseados, como las alucinaciones.

Estos sistemas combinan los conceptos de vectorización y búsqueda semántica, junto con los LLMs para retroalimentar su conocimiento con información externa que no se incluyó durante su fase de entrenamiento y que, por lo tanto, desconocen.
Existen ciertos puntos a favor de utilizar RAGs:
En contra:
Existen varios ejemplos donde los RAGs están siendo utilizados. El ejemplo más típico es su uso con chatbots para consultar información muy específica del negocio.

Vamos a hablar en detalle sobre los distintos componentes que conforman un RAG para poder tener una idea aproximada, y luego vamos a hablar de cómo interaccionan entre sí estos elementos.
Este elemento es un concepto un poco abierto pero también lógico: se refiere al conocimiento objetivo del cual sabemos que el LLM no es consciente y que tiene un alto riesgo de alucinación. Este conocimiento, en formato de texto, puede estar en muchos formatos: PDF, Excel, Word, etc… Los RAGs avanzados son capaces también de detectar conocimientos en imágenes y tablas.
En general, todo contenido va a ser en formato de texto y va a necesitar ser indexado. Como los textos humanos son muchas veces desestructurados, se recurre a la subdivisión de los textos con estrategias llamadas chunking.
Un embedding es la representación vectorial generada por una red neuronal entrenada sobre un cuerpo de datos (texto, imágenes, sonido, etc.) que es capaz de resumir la información de un objeto de ese mismo tipo hacia un vector dentro de un espacio vectorial concreto.
Por ejemplo, en el caso de un texto que se refiere a “Me gustan los patitos de goma azules” y otro que dice “Adoro los patitos de goma amarillos”, al ser convertidos en vectores, estos estarán más próximos en distancia entre sí que un texto que se refiere a “Los automóviles del futuro son los coches eléctricos”.
Este componente es el que, posteriormente, nos permitirá indexar de forma correcta los distintos chunks de información de texto.
Es el lugar donde vamos a guardar y indexar la información vectorial de los chunks mediante los embeddings. Se trata de un componente muy importante y complejo donde, afortunadamente, ya existen varias soluciones open source muy válidas para poder desplegarlo de forma «fácil», como Milvus o Chroma.
Es lógico, puesto que el RAG es una solución que nos permite ayudar a responder de forma más veraz a estos LLMs. No tenemos por qué restringirnos a modelos muy grandes y eficientes (pero no económicos como GPT-4), sino que pueden ser modelos más pequeños y más «sencillos» en cuanto a la calidad de respuestas y número de parámetros.
A continuación podemos ver una imagen representativa del proceso de carga de información en la base de datos vectoriales.

Ahora que tenemos un poco más claras las piezas del rompecabezas, surgen algunas dudas:
Vamos a intentar esclarecer un poco el asunto.

La idea intuitiva del funcionamiento de un RAG es la siguiente:
Es por eso que necesitamos un embedding y la base de datos vectorial. Ahí está un poco el truco. Si eres capaz de encontrar información muy parecida a tu pregunta en tu base de datos vectorial, entonces puedes detectar contenido que puede ser de utilidad para tu pregunta. Pero para todo ello, necesitamos un elemento que nos permita poder comparar textos de forma objetiva y esa información no podemos tenerla guardada de forma desestructurada si necesitamos hacer preguntas de forma frecuente.
También, que al final todo esto termina en el prompt, que nos permite que sea un flujo independiente del modelo de LLM que vayamos a usar.
De igual manera que los modelos de estadística o ciencias de datos más clásicos, tenemos una necesidad de cuantificar cómo está funcionando un modelo antes de utilizarlo de manera productiva.
La estrategia más básica (por ejemplo, para medir la efectividad de una regresión lineal) consiste en dividir el conjunto de datos en distintas partes como train y test (80 y 20% respectivamente), entrenando el modelo en train y evaluando en test con métricas como el root-mean-square error, dado que el conjunto de test son datos que no ha visto el modelo. Sin embargo, un RAG no consta de entrenamiento sino de un sistema compuesto de distintos elementos donde una de sus partes es usar un modelo de generación de texto.
Más allá de esto, aquí ya no tenemos datos cuantitativos (es decir, números) y la naturaleza del dato consiste en texto generado que puede variar en función de la pregunta que le hagamos, el contexto detectado por el sistema de Retrieval y incluso el comportamiento no determinista que tienen los modelos de redes neuronales.
Una estrategia básica que podemos pensar es en ir analizando a mano qué tan bueno está funcionando nuestro sistema, en base a hacer preguntas y ver cómo están funcionando las respuestas y los contextos devueltos. Pero este enfoque se vuelve impracticable cuando queremos evaluar todas las posibilidades de preguntas en documentos muy grandes y de forma recurrente.
¿Entonces, cómo podemos hacer esta evaluación?
El truco: Aprovechando los propios LLMs. Con ellos podemos construir un conjunto de datos sintético con el que se haya simulado la misma acción de hacer preguntas a nuestro sistema, tal como si un humano lo hubiera hecho. Incluso le podemos añadir un nivel de fineza mayor: utilizar un modelo más inteligente que el anterior y que funcione como un crítico, que nos indique si lo que está sucediendo tiene sentido o no.

Aquí lo que tenemos son muestras de Pregunta-Respuesta de cómo hubiera funcionado nuestro sistema de RAG simulando las preguntas que le podría hacer un humano en comparativa al modelo que estamos evaluando. Para hacer esto, necesitamos dos modelos: el LLM que utilizaríamos en nuestro RAG, por ejemplo, GPT-3.5-turbo (Answer) y otro modelo con mejor funcionamiento para generar una “verdad” (Ground Truth), como GPT-4.
Es decir, en otras palabras, el ChatGPT 3.5 sería el sistema generador de preguntas y el ChatGPT 4 sería como la parte crítica.
Una vez generado nuestro conjunto de datos de evaluación, lo que nos queda es cuantificar numéricamente con algún tipo de métrica.
La evaluación de las respuestas es algo nuevo pero ya existen proyectos de código abierto que logran cuantificar de forma efectiva la calidad de los RAGs. Estos sistemas de evaluación permiten medir la parte de «Retrieval» y «Generation» por separado.

Mide la veracidad de nuestras respuestas dado un contexto. Es decir, con qué porcentaje lo que se pregunta es verdad en función del contexto conseguido a través de nuestro sistema. Esta métrica sirve para intentar controlar las alucinaciones que pueden tener los LLMs. Un valor muy bajo en esta métrica implicaría que el modelo se está inventando cosas, aunque se le dé un contexto. Por lo tanto, es una métrica que debe estar lo más cercano a uno.
Cuantifica la relevancia de la respuesta en base a la pregunta que se le hace a nuestro sistema. Si la respuesta no es relevante a lo que le preguntamos, no nos está respondiendo adecuadamente. Por lo tanto cuanto más alta sea esta métrica, mejor.
Evalua si todos los elementos de nuestros ground-truth ítems dentro de los contextos, son rankeados de forma prioritaria o no.
Cuantifica si el contexto devuelto se alinea con la respuesta anotada. En otras palabras, cómo de relevante es el contexto respecto a la pregunta que hacemos. Una valor bajo indicaría que el contexto devuelto es poco relevante y no nos ayuda a responder la pregunta.

El cómo todas estas métricas se están evaluando es un poco más complejo pero podemos encontrar ejemplos bien explicados en la documentación de RAGAS.
Vamos a utilizar el framework de LangChain que nos permite construir un RAG de forma muy fácil.
El dataset que vamos a utilizar es un ensayo de Paul Graham, un dataset típico y pequeño en cuanto a tamaño.
La base de datos vectorial que vamos a utilizar va a ser Chroma, open-source y con plena integración con LangChain. El uso de esta va a ser completamente transparente, utilizando los parámetros por defecto.
NOTA: Cada llamada a un modelo asociado, tiene un coste monetario y conviene revisar el pricing de OpenAI. Nosotros vamos a trabajar con un dataset pequeño de 10 preguntas pero si se escalase, el coste podría incrementarse.
import os
from dotenv import load_dotenv
load_dotenv() # Configurar OpenAI API Key
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.prompts import ChatPromptTemplate
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 700,
chunk_overlap = 50
)
loader = TextLoader('paul_graham/paul_graham_essay.txt')
text = loader.load()
documents = text_splitter.split_documents(text)
print(f'Número de chunks generados gracias al documento: {len(documents)}')
vector_store = Chroma.from_documents(documents, embeddings)
retriever = vector_store.as_retriever() Número de chunks generados gracias al documento: 158
Dado que el texto del libro está en inglés, debemos de hacer nuestro template de prompt esté en inglés.
from langchain.prompts import ChatPromptTemplate
template = """Answer the question based only on the following context. If you cannot answer the question with the context, please respond with 'I don't know':
Context:
{context}
Question:
{question}
"""
prompt = ChatPromptTemplate.from_template(template) Ahora vamos a definir nuestro RAG mediante LCEL. El modelo a utilizar que responderá a las preguntas de nuestro RAG va a ser GPT-3.5-turbo. Importante es que el parámetro de la temperatura esté a 0 para que el modelo no sea creativo.
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
primary_qa_llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
retrieval_augmented_qa_chain = (
{"context": itemgetter("question") | retriever, "question": itemgetter("question")}
| RunnablePassthrough.assign(context=itemgetter("context"))
| {"response": prompt | primary_qa_llm, "context": itemgetter("context")}
) .. y ahora es posible hacerle ya preguntas a nuestro sistema RAG.
question = "What was doing the author before collegue? "
result = retrieval_augmented_qa_chain.invoke({"question" : question})
print(f' Answer the question based: {result["response"].content}') Answer the question based: The author was working on writing and programming before college.
También podemos investigar cuales han sido los contextos devueltos por nuestro retriever. Como hemos mencionado, la estrategia de Retrieval es la por defecto y nos devolverá los top 4 contextos para responder a una pregunta.
display(retriever.get_relevant_documents(question))
display(retriever.get_relevant_documents(question))
[Document(page_content="What I Worked On\n\nFebruary 2021\n\nBefore college the two main things I worked on, outside of school, were writing and programming. I didn't write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.", metadata={'source': 'paul_graham/paul_graham_essay.txt'}),
Document(page_content="Over the next several years I wrote lots of essays about all kinds of different topics. O'Reilly reprinted a collection of them as a book, called Hackers & Painters after one of the essays in it. I also worked on spam filters, and did some more painting. I used to have dinners for a group of friends every thursday night, which taught me how to cook for groups. And I bought another building in Cambridge, a former candy factory (and later, twas said, porn studio), to use as an office.", metadata={'source': 'paul_graham/paul_graham_essay.txt'}),
Document(page_content="In the print era, the channel for publishing essays had been vanishingly small. Except for a few officially anointed thinkers who went to the right parties in New York, the only people allowed to publish essays were specialists writing about their specialties. There were so many essays that had never been written, because there had been no way to publish them. Now they could be, and I was going to write them. [12]\n\nI've worked on several different things, but to the extent there was a turning point where I figured out what to work on, it was when I started publishing essays online. From then on I knew that whatever else I did, I'd always write essays too.", metadata={'source': 'paul_graham/paul_graham_essay.txt'}),
Document(page_content="Wow, I thought, there's an audience. If I write something and put it on the web, anyone can read it. That may seem obvious now, but it was surprising then. In the print era there was a narrow channel to readers, guarded by fierce monsters known as editors. The only way to get an audience for anything you wrote was to get it published as a book, or in a newspaper or magazine. Now anyone could publish anything.", metadata={'source': 'paul_graham/paul_graham_essay.txt'})] Ahora que ya tenemos nuestro RAG montado gracias a LangChain, nos falta evaluarlo.
Parece que tanto LangChain como LlamaIndex empiezan a tener maneras de evaluar de forma fácil los RAGs sin moverse del framework. Sin embargo, por ahora, la mejor opción es utilizar RAGAS, una librería que ya habíamos mencionado y está específicamente diseñada con ese propósito. Internamente, va a utilizar GPT-4 como modelo crítico, tal y como hemos mencionado anteriormente.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
text = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 200
)
documents = text_splitter.split_documents(text)
generator = TestsetGenerator.with_openai()
testset = generator.generate_with_langchain_docs(
documents,
test_size=10,
distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25}
)
test_df = testset.to_pandas()
display(test_df) | question | contexts | ground_truth | evolution_type | episode_done | |
|---|---|---|---|---|---|
| 0 | What is the batch model and how does it relate… | [The most distinctive thing about YC is the ba… | The batch model is a method used by YC (Y Comb… | simple | True |
| 1 | How did the use of Scheme in the new version o… | [In the summer of 2006, Robert and I started w… | The use of Scheme in the new version of Arc co… | simple | True |
| 2 | How did learning Lisp expand the author’s conc… | [There weren’t any classes in AI at Cornell th… | Learning Lisp expanded the author’s concept of… | simple | True |
| 3 | How did Moore’s Law contribute to the downfall… | [[4] You can of course paint people like still… | Moore’s Law contributed to the downfall of com… | simple | True |
| 4 | Why did the creators of Viaweb choose to make … | [There were a lot of startups making ecommerce… | The creators of Viaweb chose to make their eco… | simple | True |
| 5 | During the author’s first year of grad school … | [I applied to 3 grad schools: MIT and Yale, wh… | reasoning | True | |
| 6 | What suggestion from a grad student led to the… | [McCarthy didn’t realize this Lisp could even … | reasoning | True | |
| 7 | What makes paintings more realistic than photos? | [life interesting is that it’s been through a … | By subtly emphasizing visual cues, paintings c… | multi_context | True |
| 8 | «What led Jessica to compile a book of intervi… | [Jessica was in charge of marketing at a Bosto… | Jessica’s realization of the differences betwe… | multi_context | True |
| 9 | Why did the founders of Viaweb set their price… | [There were a lot of startups making ecommerce… | The founders of Viaweb set their prices low fo… | simple | True |
test_questions = test_df["question"].values.tolist()
test_groundtruths = test_df["ground_truth"].values.tolist()
answers = []
contexts = []
for question in test_questions:
response = retrieval_augmented_qa_chain.invoke({"question" : question})
answers.append(response["response"].content)
contexts.append([context.page_content for context in response["context"]])
from datasets import Dataset # HuggingFace
response_dataset = Dataset.from_dict({
"question" : test_questions,
"answer" : answers,
"contexts" : contexts,
"ground_truth" : test_groundtruths
})
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
context_precision,
)
metrics = [
faithfulness,
answer_relevancy,
context_recall,
context_precision,
]
results = evaluate(response_dataset, metrics)
results_df = results.to_pandas().dropna() | question | answer | contexts | ground_truth | faithfulness | answer_relevancy | context_recall | context_precision | |
|---|---|---|---|---|---|---|---|---|
| 0 | What is the batch model and how does it relate… | The batch model is a system where YC funds a g… | [The most distinctive thing about YC is the ba… | The batch model is a method used by YC (Y Comb… | 0.750000 | 0.913156 | 1.0 | 1.000000 |
| 1 | How did the use of Scheme in the new version o… | The use of Scheme in the new version of Arc co… | [In the summer of 2006, Robert and I started w… | The use of Scheme in the new version of Arc co… | 1.000000 | 0.910643 | 1.0 | 1.000000 |
| 2 | How did learning Lisp expand the author’s conc… | Learning Lisp expanded the author’s concept of… | [So I looked around to see what I could salvag… | Learning Lisp expanded the author’s concept of… | 1.000000 | 0.924637 | 1.0 | 1.000000 |
| 3 | How did Moore’s Law contribute to the downfall… | Moore’s Law contributed to the downfall of com… | [[5] Interleaf was one of many companies that … | Moore’s Law contributed to the downfall of com… | 1.000000 | 0.940682 | 1.0 | 1.000000 |
| 4 | Why did the creators of Viaweb choose to make … | The creators of Viaweb chose to make their eco… | [There were a lot of startups making ecommerce… | The creators of Viaweb chose to make their eco… | 0.666667 | 0.960447 | 1.0 | 0.833333 |
| 5 | What suggestion from a grad student led to the… | The suggestion from grad student Steve Russell… | [McCarthy didn’t realize this Lisp could even … | The suggestion from a grad student, Steve Russ… | 1.000000 | 0.931730 | 1.0 | 0.916667 |
| 6 | What makes paintings more realistic than photos? | By subtly emphasizing visual cues such as the … | [copy pixel by pixel from what you’re seeing. … | By subtly emphasizing visual cues, paintings c… | 1.000000 | 0.963414 | 1.0 | 1.000000 |
| 7 | «What led Jessica to compile a book of intervi… | Jessica was surprised by how different reality… | [Jessica was in charge of marketing at a Bosto… | Jessica’s realization of the differences betwe… | 1.000000 | 0.954422 | 1.0 | 1.000000 |
| 8 | Why did the founders of Viaweb set their price… | The founders of Viaweb set their prices low fo… | [There were a lot of startups making ecommerce… | The founders of Viaweb set their prices low fo… | 1.000000 | 1.000000 | 1.0 | 1.000000 |
Visualizamos las distribuciones estadísticas que salen:
results_df.plot.hist(subplots=True,bins=20)

Podemos observar que el sistema no es perfecto aunque hemos generado solamente 10 preguntas (haría falta generar muchas más) y también se puede observar que en una de ellas, la pipeline del RAG ha fallado en crear el ground truth.
Aun así podríamos sacar algunas conclusiones:
Ahora aquí nos podemos plantear probar con distintos elementos:
Con estas posibilidades, es viable analizar cada una de esas estrategias anteriores y escoger la que mejor se ajuste a nuestros datos o criterios monetarios.
En este artículos hemos visto en qué consiste un RAG y cómo podemos evaluar un workflow completo. Todo esta materia está en auge ahora mismo dado que es una de las alternativas más eficaces y económicas para evitar el fine-tuning de los LLMs.
Es posible que se encuentren nuevas métricas, nuevos frameworks, que hagan la evaluación de estos más sencilla y eficaz; pero en los próximos artículos no solo vamos a poder ver su evolución, sino también cómo llevar a production una arquitectura basada en RAGs.